

.jpeg){kind=link}
{kind=link}
.jpeg){kind=link}
.jpeg){kind=link}
{kind=link}
AI-Powered Interview Readiness Platform is a multi-tenant SaaS platform that analyzes a candidate's CV, runs a personalized mock interview (voice or typed), and produces an explainable, multi-dimensional readiness report — not a hire/reject verdict.
Conducting consistent, unbiased candidate screening at scale is expensive and time-consuming. This platform automates the entire interview pipeline — from CV parsing to scored PDF reports — while keeping humans firmly in the decision loop.
Every "smart" feature (LLM question generation, real voice transcription, semantic scoring, body language) is optional and auto-detected: the app is fully functional with zero extra setup, and gets smarter as you install more.
🔹 Phase 1 — CV Intelligence
- PDF CV Parser — extracts skills, contact info, and experience automatically
- Personalized Question Generation — interview questions tailored to candidate's CV
- Curated skill keyword database with broad domain coverage
🔹 Phase 2 — Multi-Tenant SaaS
- Company & Candidate Accounts — separate dashboards and flows
- Custom Question Banks — companies add their own questions per role
- Configurable Interview Rounds — technical, HR, awareness rounds
🔹 Phase 3 — Voice & NLP Analysis
- Speech-to-Text — powered by faster-Whisper for real voice transcription
- Voice Confidence Scoring — pitch variation and pause ratio analysis via librosa
- Semantic Answer Scoring — sentence-transformers for relevance detection
- Typed answer fallback with TF-IDF scoring when voice is unavailable
🔹 Phase 4 — Body Language (Optional)
- Webcam Analysis — posture and eye-contact feedback via MediaPipe
- Descriptive signals only — never blocks or scores a candidate on appearance
- Fully skippable — reports "not assessed" if module not installed
🔹 Phase 5 — Reports & Dashboard
- PDF Readiness Report — detailed multi-dimensional breakdown per candidate
- Company Comparison Dashboard — side-by-side candidate comparison table
- Configurable category weights per company (Technical, Communication, Confidence, etc.)
Add your screenshots here — replace paths with raw GitHub URLs after uploading images to the repo
🏠 Candidate Dashboard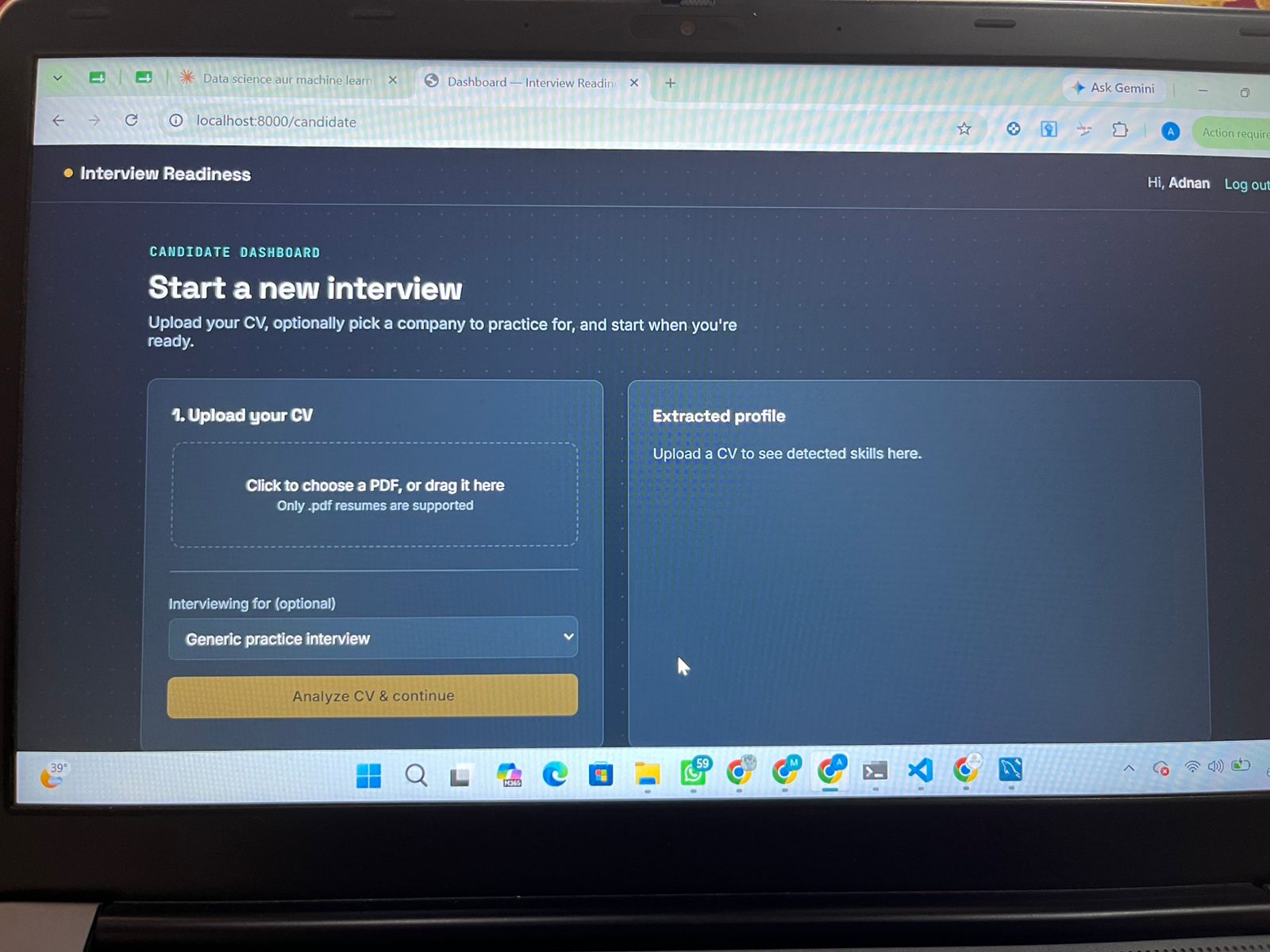
|
📄 CV Upload & Analysis.jpeg)
|
🎤 Live Interview — Voice & Typed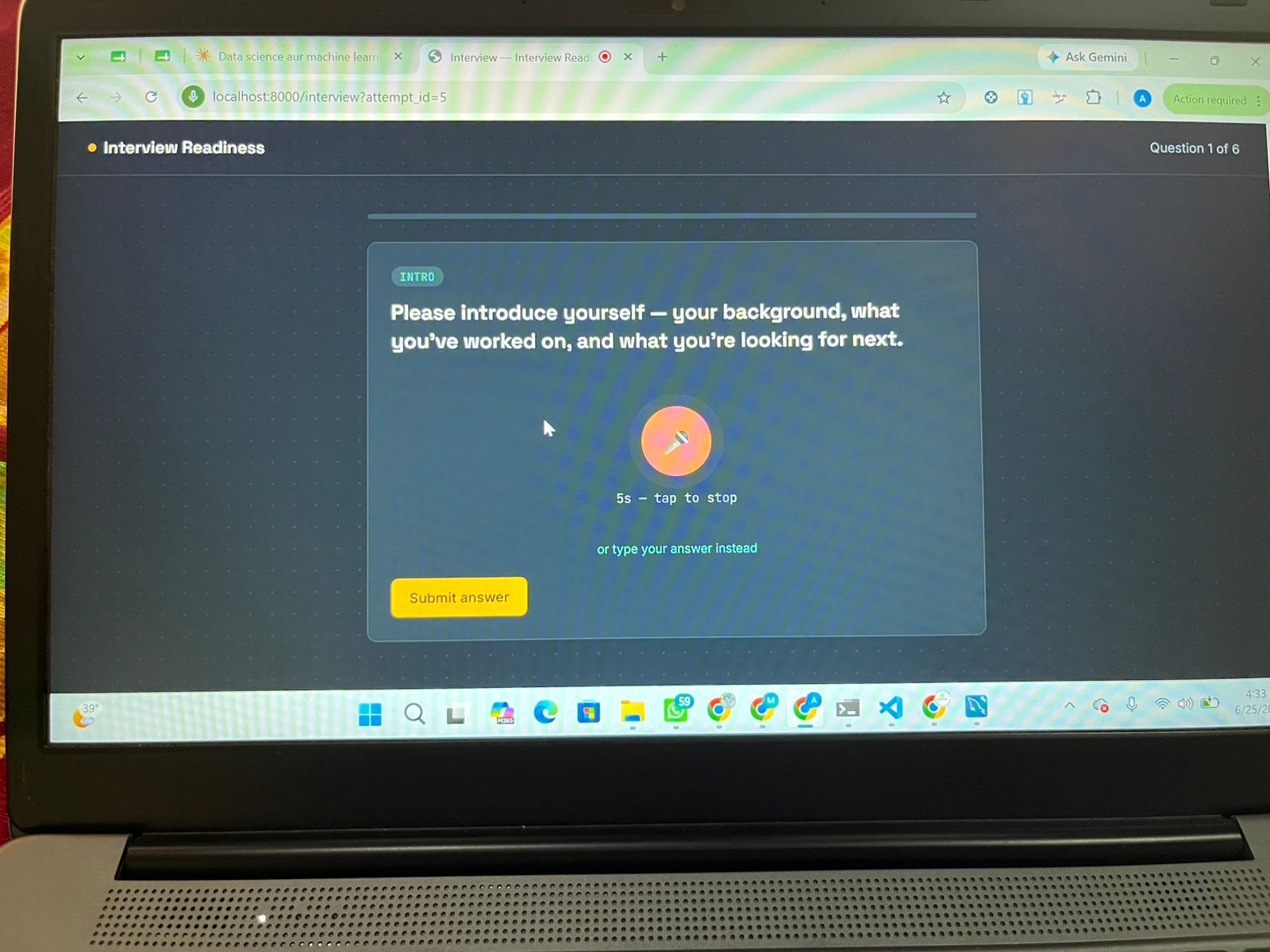
|
📊 Scoring & Results.jpeg)
|
📋 PDF Readiness Report.jpeg)
|
|
| Layer | Technology |
|---|---|
| Backend | FastAPI (Python) |
| Frontend | Plain HTML + CSS + JavaScript (no build step) |
| Database | SQLite via SQLAlchemy |
| Auth | JWT + Password Hashing |
| CV Parsing | PyMuPDF |
| Question Generation | Ollama (llama3.2) / Template Bank fallback |
| Speech-to-Text | faster-Whisper |
| Voice Analysis | librosa (pitch/pause) |
| Semantic Scoring | sentence-transformers / TF-IDF fallback |
| Body Language | MediaPipe (pose + face landmarks) |
| PDF Reports | ReportLab |
| Phase | What It Does |
|---|---|
| 1 | CV upload → skill & contact extraction → personalized question generation |
| 2 | Company + candidate accounts, custom questions, configurable rounds |
| 3 | Voice recording → speech-to-text → relevance, clarity & confidence scoring |
| 4 | Optional webcam clip → posture/eye-contact feedback (never a pass/fail score) |
| 5 | PDF readiness report + company-side candidate comparison dashboard |
# 1. Clone & setup virtual environment
git clone https://github.com/MuhammadAdnan586/interview-platform.git
cd interview-platform
python -m venv venv
venv\Scripts\activate # Windows
source venv/bin/activate # Mac/Linux
# 2. Install core dependencies
pip install -r requirements.txt
# 3. Run the server
uvicorn app.main:app --reloadOpen http://localhost:8000 — signup as a candidate or company and try the full flow immediately.
⚠️ Python 3.13+ users: ifpymupdffails to install, use Python 3.11 →py -3.11 -m venv venv
# Install from https://ollama.com, then:
ollama pull llama3.2Without this, questions come from a curated template bank — still relevant, just less varied.
pip install -r requirements-optional.txtInstalls faster-whisper and librosa. First run downloads a ~75MB Whisper model (one-time).
pip install mediapipe opencv-pythonThen download model files into models/ folder:
| Service | URL |
|---|---|
| Web App | http://localhost:8000 |
| API Docs (Swagger) | http://localhost:8000/docs |
interview-platform/
├── app/
│ ├── main.py # FastAPI app entry point
│ ├── database.py # SQLite via SQLAlchemy
│ ├── models.py # DB schema
│ ├── schemas.py # Pydantic models
│ ├── auth.py # JWT + password hashing
│ ├── cv_parser.py # PDF extraction + skill detection
│ ├── question_gen.py # Question builder (LLM / template)
│ ├── scoring.py # Relevance + clarity scoring
│ ├── voice_analysis.py # Speech-to-text + voice confidence
│ ├── body_language.py # Optional webcam analysis
│ ├── report.py # PDF report generation
│ └── routers/
│ ├── auth_routes.py # Signup / login
│ ├── cv_routes.py # CV upload & analyze
│ ├── interview_routes.py # Start / answer / complete
│ ├── admin_routes.py # Company: questions, settings
│ ├── report_routes.py # PDF download
│ └── directory_routes.py # Public company list
├── models/ # Phase 4 MediaPipe model files
├── requirements.txt # Core dependencies
├── requirements-optional.txt # Voice / semantic / body-language add-ons
└── interview_platform.db # Auto-created SQLite DB on first run
Each answer gets up to three sub-scores:
| Score | Range | Description |
|---|---|---|
| Relevance | 0–100 | Does the answer address the question's topic? |
| Clarity | 0–100 | Filler-word density, repetition, answer length |
| Confidence | 0–100 | Pitch variation & pause ratio (voice only) |
These roll up into configurable categories per company:
Technical · Communication · Confidence · Body Language · Custom Questions · Awareness
The final number is always labeled "Overall Readiness" — never "Eligible/Not Eligible". Every report explicitly states it's a signal for a human reviewer, not an automated decision.
Full interactive docs at http://localhost:8000/docs
| Method | Endpoint | Purpose |
|---|---|---|
| POST | /api/auth/signup/company |
Company registration |
| POST | /api/auth/signup/candidate |
Candidate registration |
| POST | /api/auth/login |
Login (JWT token) |
| POST | /api/cv/analyze |
Upload CV, get skills & info |
| POST | /api/interview/start |
Begin attempt, get question set |
| POST | /api/interview/{id}/answer |
Submit answer (audio or typed) |
| POST | /api/interview/{id}/body-language |
Optional webcam clip |
| POST | /api/interview/{id}/complete |
Finalize and score |
| GET | /api/interview/{id} |
Fetch attempt detail |
| GET | /api/report/{id}/pdf |
Download PDF readiness report |
| GET/POST/DELETE | /api/admin/questions |
Company custom questions |
| GET | /api/admin/candidates |
Company's candidate comparison |
Contributions are welcome! Please feel free to submit a Pull Request.
- Fork the project
- Create your feature branch (
git checkout -b feature/AmazingFeature) - Commit your changes (
git commit -m 'Add some AmazingFeature') - Push to the branch (
git push origin feature/AmazingFeature) - Open a Pull Request
Distributed under the MIT License. See LICENSE for more information.
Muhammad Adnan
Built with ❤️ using FastAPI, Python, SQLite, MediaPipe & Whisper