Machine-Speech-Translation End-to-End (EN -> VI | VI -> EN)
A Speech to Speech and Text to Text Machine Translation system using FasterWhisper for ASR, custom Transformer model for translation, and edge-tts to generate output speech.

--- Feature ---
- Automatic Speech Recognition: FasterWhisper (Large-v3 int8)
- Translation: Custom trained Transformer model (English <-> Vietnamese)
- Text to Speech: Edge-TTS for natural output sound
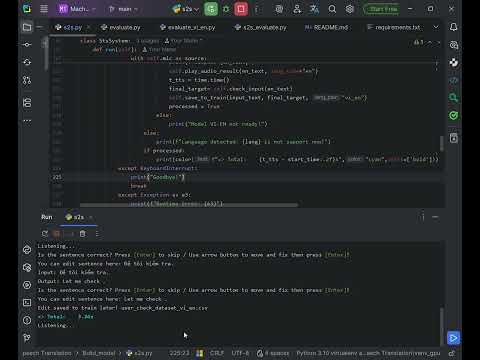
- Human-in-the-loop: User are enable to check, fix, and confirm the input and output of translation model
- Latency: Optimize for acceptable latency (2-4s for 1 sentence)
---Demo Video---
- In this video my Custom Transformer Model will translate a short basic conversation between a traveler and receptionist :
---Architecture---
- System architechture:
- Custom transformer model architecture:


--- Installation ---
- Clone the repository:
git clone [https://github.com/Secret350/Machine-Speech-Translation.git](https://github.com/Secret350/Machine-Speech-Translation.git) cd Machine Speech Translation - Install dependencies:
pip install -r requirements.txt
- Install NVIDIA Libraries (for GPU support):
pip install nvidia-cublas-cu12 nvidia-cudnn-cu12
--- How to run program ---
-
Use pre-trained model:
- First: Install weight of pre-trained model "ModelCheckpoints" by the link below then extract and place that directory in Build_model
https://drive.google.com/file/d/1D0G29vXtSGe2wyjwIKx8lJDUWhNtzsKT/view?usp=drive_link- To run Text-to-Text (EN > VI) program
cd Build_model/System_and_Evaluate python inference.py- To run Text-to-Text (VI > EN) program
cd Build_model/System_and_Evaluate python inferencevien.py- To run Speech-to-Speech (EN <> VI) program
cd Build_model python s2s.py
--- Evaluation ---
- BLEU Score (EN > VI): 22.42
- BLEU Score (VI > EN): 21.76
- BLEU Score (S2S) (EN > VI): 8.29
- BLEU Score (S2S) (VI > EN): 21.5
---Limitnations and Future Improvements---
- Limitnations:
- Model struggles with difficult/uncommon word, proper noun or too short sentences.
- The dataset lacks of many realife words.
- Future Improvements:
- Intergrating Named Entity Recognition module to solve the proper noun issue
- Retrain model with larger and more focused dataset would improve model's performance
NOTE You need to download "ffmpeg.exe" and place it in the "Build_model" folder.