We process documents related to mortgages, aka everything that happens to originate a mortgage that you don't see as a borrower. Often times the only access to a document we have is a scan of a fax of a print out of the document. Our system is able to read and comprehend that document, turning a PDF into structured business content that our customers can act on.
This dataset represents the output of the OCR stage of our data pipeline. Since these documents are sensitive financial documents we have not provided you with the raw text that was extracted. Instead we have had to obscure the data. Each word in the source is mapped to one unique value in the output. If the word appears in multiple documents then that value will appear multiple times. The word order for the dataset comes directly from our OCR layer, so it should be roughly in order.
Here is a sample line:
CANCELLATION NOTICE,641356219cbc f95d0bea231b ... [lots more words] ... 52102c70348d b32153b8b30c
The first field is the document label. Everything after the comma is a space delimited set of word values.
The dataset is included as part of this repo in ./doc_classification/model
After checking data , I found there are 14 document labels at all.
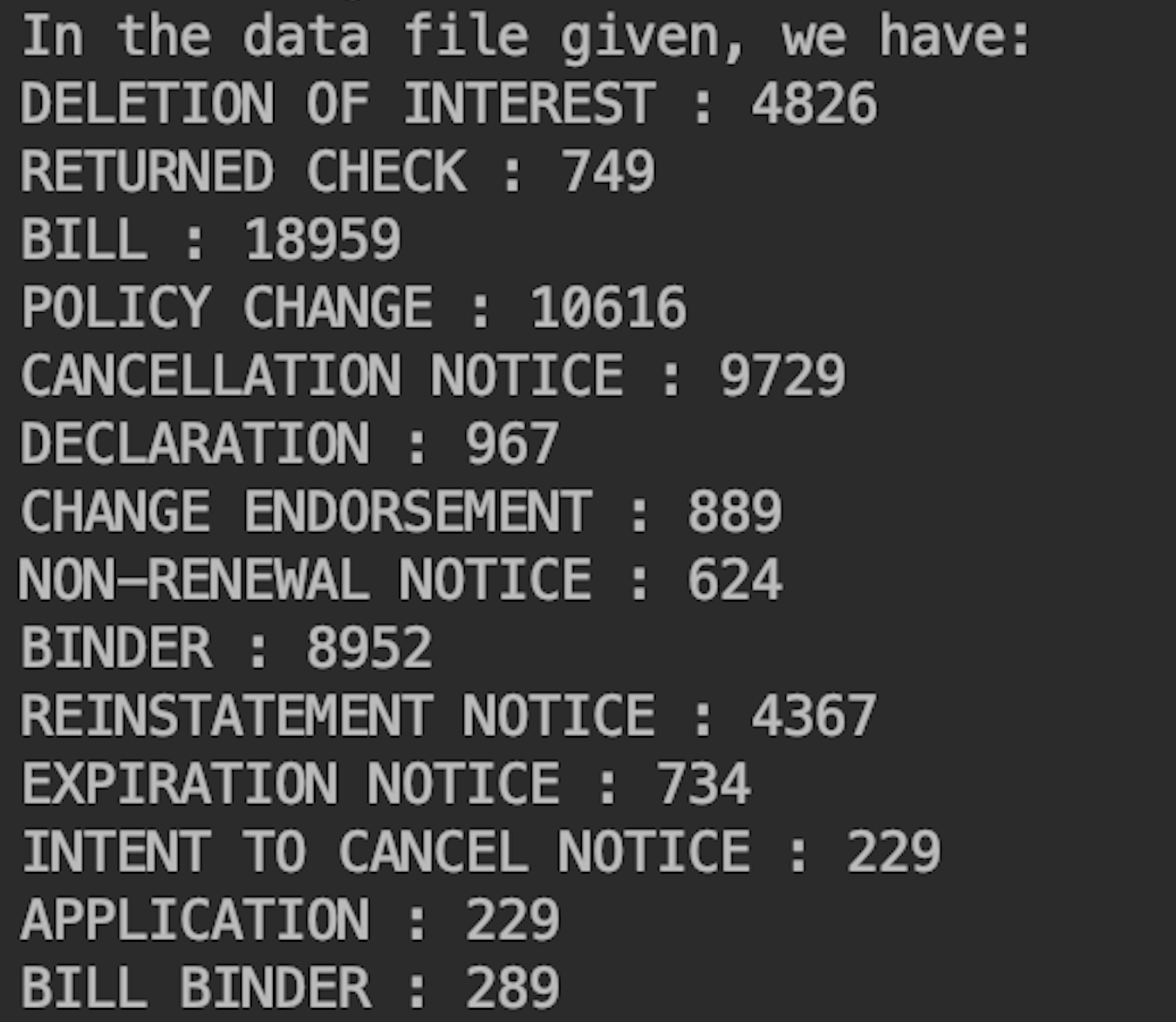
Missing Values in Data
After checking the datafiles, I found there are some missing values in both labels line and comment line. So, some pretreatment to avoid these 'noise' was necessary:
if len(c) == 0 or l not in ['DECLARATION', 'EXPIRATION NOTICE', 'BILL BINDER', 'APPLICATION', 'NON-RENEWAL NOTICE', 'INTENT TO CANCEL NOTICE', 'DELETION OF INTEREST', 'BINDER', 'POLICY CHANGE', 'RETURNED CHECK', 'REINSTATEMENT NOTICE', 'CHANGE ENDORSEMENT', 'BILL', 'CANCELLATION NOTICE']:
continue
Training Data & Testing Data
In this model, I split the data into 2 parts with ratio: 8:2, where the first part was used for training and the second for testing.
train_labels, test_labels, train_wids, test_wids = train_test_split(labels, ls_of_wid, test_size = 0.2)
Statistical Methods
In this project, I used TF-IDF(term frequency–inverse document frequency) to create sentence vectors.
Generate Model
I used Naive Bayes model available in the scikit-learn. After splitting the data into 80% train and 20% test, this model predicted the test data with about 73% accuracy.

UPDATE: I applyed Decision Tree Model and it predicted the test data with about 82% accuracy!
Save and Read Model
Use pickle to save and read the model:
with open('model.pickle', 'wb') as f:
pickle.dump(classifier, f, protocol=pickle.HIGHEST_PROTOCOL)
with open('./model/model.pickle', 'rb') as f:
classifier = pickle.load(f)
I used Django which is a framework written in Python to create this website project.
I used html, css and Bootstrap to develop and modify the web page, like the inputfield and submit bottom.
Restful API.
AWS lambda
AWS Lambda is a serverless computing platform by amazon, which is completely event driven and it automatically manages the computing resources. It scales automatically when needed, depending upon the requests the application gets.
Zappa
Zappa is a python framework used for deploying python applications onto AWS-Lambda. Zappa handles all of the configuration and deployment automatically for us.
Deployment
The prediction function is deployed on AWS lambda with the help of Zappa, and the model and required packages for the functions are stored on AWS S3. For security, contact me at shurancn@gmail.com if you want to access the deployed website :)
Step 1
Enroll in the envirnment: source bin/avtivate
Step 2
cd doc_classification, then Install all the needed packages: pip3 install -r requirements.txt
Step 3
cd doc_classification, python3 manage.py migrate, then run the server: python3 manage.py runserver
PS: To access the code of training model, go to
./doc_classification/doc_classification/model/train_model.py
- Different ML models like SVM, Logistic Regression and Decision Trees should be tested and compared, I didn't try this time due to time constraint.
- Before hashing ouput from OCR layer, removing stop-words can be done to get better classification.