

This code is released under GPL v.2.0 and implements in Python the SAX toolkit and the algorithms built on top of it:
- Symbolic Aggregate approXimation (SAX) -- discretizing a time series into a string, with z-Normalization and PAA [1]
- HOT-SAX -- an algorithm for the exact time series discord (anomaly) discovery [3]
- RePair -- a grammar-inference algorithm run over the SAX representation [7]
- RRA (Rare Rule Anomaly) -- a grammar-based, variable-length discord discovery algorithm built on RePair [8]
- SAX-VSM -- an algorithm for interpretable time series classification (and its discretization parameters optimization) [5]
- SAX-ENERGY, SAX-REPEAT, SAX-INDEPENDENT -- extensions of SAX to multi-dimensional time series [4]
Note that most of this functionality is also implemented in R (the jmotif package on CRAN) and in Java; the SAX-VSM classifier specifically also lives in the Java sax-vsm_classic project, and the grammar-based anomaly work in GrammarViz. These implementations are kept aligned -- see the next section.
The Python (saxpy), R, and Java implementations are kept aligned: the SAX stack -- z-Normalization, PAA, Gaussian breakpoints, symbol assignment -- and the HOT-SAX / brute-force discord search produce the same results across all three to floating-point precision. The shared conventions are:
- z-Normalization uses the population standard deviation (divide by
n), matching the Matrix Profile / MASS convention, so each window has empirical variance exactly 1 (the assumption behind SAX's equiprobable breakpoints); - PAA uses fractional segment boundaries (a sample straddling a segment edge is split by overlap);
- a value falling exactly on a breakpoint maps to the symbol above the cut;
- all distance-based discord search compares z-normalized subsequences -- HOT-SAX, brute-force, and RRA key on shape, not amplitude; HOT-SAX and brute-force additionally break distance ties by the lowest index, so their results are reproducible regardless of search order.
RRA agrees with the others on the discord region (e.g. the ecg0606 anomaly at position 430), but its reported nearest-neighbour distance is a search-order-dependent approximation: the rarest-first search early-abandons as soon as a close-enough neighbour is found, so the exact distance value (not the position) can differ by a few percent between implementations whose random visit orders differ. This is inherent to the heuristic, not a convention gap.
SAX-VSM is aligned too. The TF*IDF weight uses log1p term frequency, ln(1 + tf), and a natural-log IDF, ln(N / df) in saxpy, jmotif-R, and the Java sax-vsm_classic (which previously used the SMART 1 + ln(tf) / log10 scheme). A cross-implementation accuracy study (CBF, Gun_Point, Coffee, Beef, OSULeaf, Adiac) found log1p ties or beats SMART at the tuned operating point on every dataset and wins more parameter points overall, so log1p is now canonical. Note that the IDF base (ln vs log10) is a uniform per-word factor that cancels in the cosine -- it never affects a classification, only the printed weight magnitudes; the TF nonlinearity is the only behavioural lever. On the shared Cylinder-Bell-Funnel set all three score identically (900/900 at window 60 / PAA 8 / alphabet 6, EXACT numerosity reduction).
saxpy is published on PyPI, install it with pip (or uv pip):
$ pip install saxpy
saxpy requires Python 3.10+ and depends on numpy, scipy, and scikit-learn. The example data used in this README (data/ecg0606_1.csv, resources/data/cbf/) ships in the source tree, so the file-reading examples below assume you are running from a repository clone; a pip-installed wheel contains the code only.
The project uses uv for environment management and packaging (PEP 621 / pyproject.toml, Hatchling build backend). From a clone:
$ uv sync # create the venv and install saxpy + dev tools
$ uv run pytest # run the test suite (unit tests + doctests)
$ uv run ruff check # lint
$ uv run ruff format # format
$ uv run mypy saxpy # type-check
The tests run across all supported interpreters via uv run --python 3.10/3.11/3.12 pytest; uv build produces a wheel + sdist in dist/; uv run pre-commit install enables the ruff + mypy hooks.
SAX transforms a sequence of rational numbers (i.e., a time series) into a sequence of letters (i.e., a string). An illustration of a 128-point time series converted into a word of 8 letters:
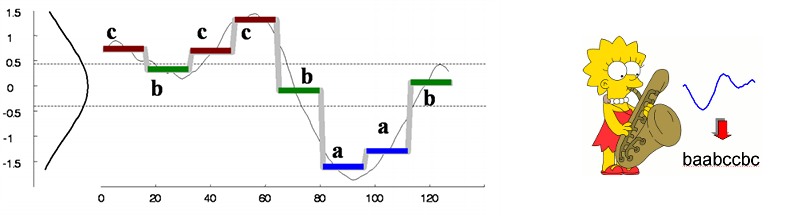
As discretization is probably the most used transformation in data mining, SAX has been widely used throughout the field. Find more information about SAX at its authors' pages: SAX overview by Jessica Lin, Eamonn Keogh's SAX page, or at the sax-vsm wiki page.
To convert a time series of an arbitrary length to SAX we first need to define the alphabet cuts. Saxpy retrieves cuts for a Normal alphabet (we use size 3 here) via cuts_for_asize:
from saxpy.alphabet import cuts_for_asize
cuts_for_asize(3)
which yields an array (the leading -inf is the lower sentinel, so the array has alphabet_size entries):
array([ -inf, -0.4307273, 0.4307273])
To convert a time series to letters we use ts_to_string, not forgetting to z-Normalize the input first:
import numpy as np
from saxpy.znorm import znorm
from saxpy.sax import ts_to_string
ts_to_string(znorm(np.array([-2, 0, 2, 0, -1])), cuts_for_asize(3))
which produces a string:
'abcba'
In order to reduce dimensionality further, PAA (Piecewise Aggregate Approximation) is usually applied before SAX. PAA splits the series into equally-sized segments and averages the points within each, so the example above reduces from five points to three letters:
import numpy as np
from saxpy.znorm import znorm
from saxpy.paa import paa
from saxpy.sax import ts_to_string
from saxpy.alphabet import cuts_for_asize
dat = np.array([-2, 0, 2, 0, -1])
dat_paa_3 = paa(znorm(dat), 3)
ts_to_string(dat_paa_3, cuts_for_asize(3))
and a three-letter string is produced:
'acb'
The two steps are also available as a single call, sax_by_chunking(series, paa_size, alphabet_size, znorm_threshold=0.01), which z-Normalizes, PAA-reduces, and discretizes in one shot:
from saxpy.sax import sax_by_chunking
sax_by_chunking(np.array([-2., 0, 2, 0, -1, 1, 3, 1, 0]), paa_size=3, alphabet_size=3)
# 'bbc'
Typically, to investigate the structure of a time series -- to discover anomalous (i.e., discords) and recurrent (i.e., motifs) patterns -- we convert it to SAX via a sliding window. Saxpy implements this workflow in sax_via_window:
import numpy as np
from saxpy.sax import sax_via_window
dat = np.array([0., 0., 0., 0., 0., -0.270340178359072, -0.367828308500142,
0.666980581124872, 1.87088147328446, 2.14548907684624,
-0.480859313143032, -0.72911654245842, -0.490308602315934,
-0.66152028906509, -0.221049033806403, 0.367003418871239,
0.631073992586373, 0.0487728723414486, 0.762655178750436,
0.78574757843331, 0.338239686422963, 0.784206454089066,
-2.14265084073625, 2.11325193044223, 0.186018356196443,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.519132472499234,
-2.604783141655, -0.244519550114012, -1.6570790528784,
3.34184602886343, 2.10361226260999, 1.9796808733979,
-0.822247322003058, 1.06850578033292, -0.678811824405992,
0.804225748913681, 0.57363964388698, 0.437113583759113,
0.437208643628268, 0.989892093383503, 1.76545983424176,
0.119483882364649, -0.222311941138971, -0.74669456611669,
-0.0663660879732063, 0., 0., 0., 0., 0.,])
sax_via_window(dat, win_size=6, paa_size=3, alphabet_size=3, nr_strategy=None, znorm_threshold=0.01)
the result maps each SAX word to the list of start positions where it occurred:
defaultdict(list,
{'aac': [4, 10, 11, 30, 35],
'abc': [12, 14, 36, 44],
'acb': [5, 16, 21, 37, 43],
'acc': [13, 52, 53, 54],
'bac': [3, 19, 34, 45, 51],
'bba': [31],
'bbb': [15, 18, 20, 22, 25, 26, 27, 28, 29, 41, 42, 46],
'bbc': [2],
'bca': [6, 17, 32, 38, 47, 48],
'caa': [8, 23, 24, 40],
'cab': [9, 50],
'cba': [7, 39, 49],
'cbb': [33],
'cca': [0, 1]})
sax_via_window is the hub almost everything downstream calls. Its full signature:
def sax_via_window(series, win_size, paa_size, alphabet_size=3,
nr_strategy='exact', znorm_threshold=0.01, sax_type='unidim')
nr_strategy is the numerosity reduction strategy ('exact', 'mindist', or None) that collapses runs of the same/near-identical consecutive word. sax_type selects the per-window strategy: 'unidim' (the default, for 1-D series) and the three multi-dimensional modes below.
For a multi-dimensional series (an n x d array of n timestamps over d dimensions), sax_type selects how the dimensions are combined [4]:
'independent'-- SAX-encode each dimension on its own and concatenate the per-dimension words;'energy'-- z-Normalize across dimensions and aggregate the per-dimension energy;'repeat'-- run standard SAX per dimension, then k-means-cluster the multi-dimensional words into the requested alphabet.
For example, on a 12-point, 2-dimensional series with the independent mode:
import numpy as np
from saxpy.sax import sax_via_window
mts = np.column_stack([np.sin(np.linspace(0, 3, 12)),
np.cos(np.linspace(0, 3, 12))])
sax_via_window(mts, win_size=6, paa_size=3, alphabet_size=3,
nr_strategy="none", znorm_threshold=0.01, sax_type="independent")
# {'abccba': [0, 1], 'acccba': [2], 'acbcba': [3], 'ccacba': [4], 'cbacba': [5, 6]}
each six-letter word is the 3-letter word of dimension 0 followed by that of dimension 1.
Saxpy implements the HOT-SAX discord discovery algorithm in find_discords_hotsax:
import numpy as np
from numpy import genfromtxt
from saxpy.hotsax import find_discords_hotsax
dd = genfromtxt("data/ecg0606_1.csv", delimiter=',')
find_discords_hotsax(dd)
which finds the anomalies as (position, nearest-neighbour distance) pairs:
[(430, np.float64(5.279080006171839)), (318, np.float64(4.175756357308695))]
The function is parameterized with the sliding window size, the number of discords desired, the PAA and alphabet sizes, and the z-Normalization threshold:
def find_discords_hotsax(series, win_size=100, num_discords=2, paa_size=3,
alphabet_size=3, znorm_threshold=0.01, sax_type='unidim')
For verifying discords or measuring the HOT-SAX speed-up, saxpy also ships a reference O(n²) brute-force search, find_discords_brute_force(series, win_size, num_discords=2, znorm_threshold=0.01):
from saxpy.discord import find_discords_brute_force
find_discords_brute_force(dd[100:500], 100, 2)
# [(73, 6.198555329625454), (219, 5.563692399101613)]
Both searches take an optional random_state for a reproducible search trajectory; the discords themselves are deterministic (lowest-index tie-break) regardless of the seed.
Saxpy infers a RePair grammar from a space-delimited string of SAX words (or any tokens) via str_to_repair_grammar, which returns a dict mapping rule_id to a RepairRule. Rule 0 (R0) is the compressed top-level string:
from saxpy.repair import str_to_repair_grammar
g = str_to_repair_grammar("abc abc cba cba bac xxx abc abc cba cba bac")
g[0].rule_string # 'R4 xxx R4'
g[4].expanded_rule_string # 'abc abc cba cba bac'
RePair is lossless and the grammar is structurally equivalent across the R, Python, and Java implementations: decompressing R0 always reproduces the input, and R0 ends up with no repeated digram. RePair works by repeatedly replacing the most frequent digram with a new rule; when several digrams share the maximal frequency, which one is replaced first is an implementation detail (saxpy follows Python dict insertion order, the C++/R port follows unordered_map iteration, Java uses a priority queue). On tie-heavy inputs this can change the rule numbering and which equal-frequency pair gets factored -- so the rule ids and even the rule count may differ slightly between implementations -- but the compression is correct in all of them. Treat rule_id as implementation-local, not a cross-language identifier.
The Rare Rule Anomaly (RRA) algorithm builds a RePair grammar over the SAX representation, derives variable-length subsequences from the grammar rules, and searches them rarest-first. It is exposed as find_discords_rra:
import numpy as np
from numpy import genfromtxt
from saxpy.rra import find_discords_rra
dd = genfromtxt("data/ecg0606_1.csv", delimiter=',')
find_discords_rra(dd, win_size=100, num_discords=2)
which returns a list of RRADiscord records (variable-length, with start/end positions and the nearest-neighbour distance):
[RRADiscord(rule_id=76, start=1722, end=1870, length=148, nn_distance=0.05577536309246554),
RRADiscord(rule_id=35, start=430, end=531, length=101, nn_distance=0.05258209490111305)]
As noted in the alignment section, nn_distance is computed between z-normalized subsequences (so RRA keys on shape, like HOT-SAX), and because the rarest-first search early-abandons it is a search-order-dependent approximation of the true nearest-neighbour distance; the discord positions are stable. The signature:
def find_discords_rra(series, win_size, paa_size=3, alphabet_size=3,
nr_strategy="none", znorm_threshold=0.01, num_discords=2,
random_state=None)
SAX-VSM turns each training class into a single "bag of words" of SAX patterns, weights those with TF*IDF, and classifies a new series by the class whose weight vector is closest in cosine angle [5]. Saxpy ships the building blocks (series_to_wordbag, manyseries_to_wordbag, bags_to_tfidf, cosine_distance, class_for_bag) and, on top of them, a convenience layer (load_ucr_data, train_tfidf, classify_series, classification_accuracy).
Using the Cylinder-Bell-Funnel dataset that ships in the repository:
from saxpy.saxvsm import load_ucr_data, train_tfidf, classification_accuracy
# UCR/jMotif text format: class label in column 0, series values after.
train = load_ucr_data("resources/data/cbf/CBF_TRAIN") # {'1': [...], '2': [...], '3': [...]}
test = load_ucr_data("resources/data/cbf/CBF_TEST")
# build the per-class TF*IDF vectors, then score the test split
tfidf = train_tfidf(train, win_size=60, paa_size=8, alphabet_size=6,
nr_strategy="exact", znorm_threshold=0.01)
classification_accuracy(test, tfidf, 60, 8, 6, "exact", 0.01)
# 1.0 -- a perfect score on CBF at these parameters
bags_to_tfidf takes an optional tf_scheme ("log1p", the default ln(1 + tf), or "smart", 1 + ln(tf)); see the cross-implementation note above for why log1p is canonical. To classify a single series, use classify_series(series, tfidf, win_size, paa_size, ...), which returns the predicted label (or None when every class ties).
The window / PAA / alphabet sizes are the hidden parameters of SAX-VSM, and the right choice is not obvious. saxpy can select them automatically by minimizing the leave-out cross-validation error on the training set with the DIRECT global optimizer (scipy.optimize.direct) -- the same recipe used by the Java DiRect sampler and the jmotif-R README:
import numpy as np
from saxpy.saxvsm_optimize import optimize_parameters
X = np.array([s for series in train.values() for s in series])
y = np.array([lbl for lbl, series in train.items() for _ in series])
optimize_parameters(X, y, max_iter=10, random_state=0)
# {'window_size': 65, 'paa_size': 12, 'alphabet_size': 4,
# 'cv_error': 0.0, 'nfev': 11, 'evaluations': [...]}
optimize_parameters is deterministic for a fixed random_state; the underlying CV objective is exposed separately as cv_error(train_data, train_labels, params, ...) if you want to score a single parameter point. Run independently, saxpy, jmotif-R, and Java each pick their own optimum and reach the same test accuracy on the datasets we checked (CBF, Coffee, Gun_Point, Beef).
Not yet implemented in saxpy. EMMA (the complement to HOT-SAX -- recurrent motifs rather than discords) is available in the sibling Java project; a Python port is planned.
The tables below characterize the time and peak-memory behaviour of the saxpy algorithms as a function of series length. Each row is a real, non-periodic signal at that length (tiling/exact repetition makes the discord search pathological, so it is avoided), discretized with win=100, paa=4, alphabet=4, finding two discords. Measured on an AMD Ryzen 9 5950X (single core, Python 3.12) with a standalone profiling harness. Because each length is a different signal, read the columns as real-world cost at that scale, not a controlled same-signal scaling curve.
Wall-clock (seconds, best of repeated runs):
| n | dataset | SAX via window | HOT-SAX | brute-force | RePair | RRA |
|---|---|---|---|---|---|---|
| 2,299 | ecg0606 | 0.16 | 0.82 | 0.82 | 0.005 | 2.08 |
| 5,400 | stdb_308 | 0.38 | 9.36 | 4.28 | 0.009 | 18.94 |
| 21,600 | mitdbx_108 | 1.52 | 19.31 | 76.53 | 0.030 | 77.22 |
| 35,039 | dutch_power | 2.49 | 71.50 | 232.44 | 0.066 | 195.97 |
Peak memory (MiB above baseline, via tracemalloc):
| n | dataset | SAX via window | HOT-SAX | brute-force | RePair | RRA |
|---|---|---|---|---|---|---|
| 2,299 | ecg0606 | 0.1 | 3.7 | 3.9 | 0.2 | 1.2 |
| 5,400 | stdb_308 | 0.1 | 8.9 | 9.3 | 0.5 | 2.5 |
| 21,600 | mitdbx_108 | 0.3 | 35.9 | 37.8 | 1.3 | 9.6 |
| 35,039 | dutch_power | 0.6 | 58.4 | 61.8 | 2.6 | 16.4 |
A few things this makes concrete: sax_via_window and RePair are effectively linear and cheap (RePair runs over the SAX word string, not the raw series); the brute-force reference and HOT-SAX are the O(n²) distance searches (the vectorized brute-force is the exact reference -- HOT-SAX's heuristic ordering is what buys the speed-up on the smaller, structured series, while on a long noisy signal the two converge in cost); and RRA, being variable-length and grammar-driven, is the heaviest in pure Python at large n (the compiled R/Java RRA is faster in absolute terms -- this is the interpreter gap, not an algorithmic difference).
SAX-VSM (Cylinder-Bell-Funnel, 30 train / 900 test):
| operation | wall-clock | peak memory |
|---|---|---|
train_tfidf + classification_accuracy (all 900 test series) |
8.6 s | 0.5 MiB |
optimize_parameters (max_iter=10, leave-out CV) |
86.0 s | 1.8 MiB |
saxpy 2.0.0 is the first modern PyPI release (the only prior artifact was the legacy 1.0.1.dev167 pbr snapshot). The full list is in CHANGELOG.md; the highlights:
- New: SAX-VSM classification -- the classifier layer (§7.0) and a DIRECT cross-validation parameter optimizer (§7.1), verified identical to the R and Java implementations on CBF.
- New: the grammar layer -- RePair grammar inference (§5.0) and RRA variable-length discord discovery (§6.0), ported from the C++/Java.
- New: reproducibility -- an optional
random_stateon the HOT-SAX, brute-force, and RRA discord searches. - Cross-implementation alignment -- the SAX stack, the discord distances, and the SAX-VSM
log1pTF*IDF are now aligned to R and Java (see the alignment section). Several outputs near a breakpoint differ from the 1.x line as a result. - Performance -- a bucketed priority queue for RePair (~2.8×), a lighter RRA z-Norm path (~3--6×), and vectorized PAA.
- Modernized packaging & tooling -- pbr → Hatchling,
uv+pyproject.toml, ruff + mypy gates, and a 3.10/3.11/3.12 × linux/macOS/windows CI matrix. The minimum Python is now 3.10. - Renamed
cosine_similarity→cosine_distance(it returns1 - cosine); the old name is kept as a deprecated alias.
[1] Lin, J., Keogh, E., Patel, P., and Lonardi, S., Finding Motifs in Time Series, The 2nd Workshop on Temporal Data Mining, the 8th ACM Int'l Conference on KDD (2002)
[2] Patel, P., Keogh, E., Lin, J., Lonardi, S., Mining Motifs in Massive Time Series Databases, In Proc. ICDM (2002)
[3] Keogh, E., Lin, J., Fu, A., HOT SAX: Efficiently finding the most unusual time series subsequence, In Proc. ICDM (2005)
[4] Mohammad, Y., Nishida T., Robust learning from demonstrations using multidimensional SAX, 2014 14th International Conference on Control, Automation and Systems (ICCAS 2014)
[5] Senin, P., and Malinchik, S., SAX-VSM: Interpretable Time Series Classification Using SAX and Vector Space Model, Data Mining (ICDM), 2013 IEEE 13th International Conference on, pp. 1175-1180 (2013)
[6] Salton, G., Wong, A., Yang, C., A vector space model for automatic indexing, Commun. ACM 18, 11, 613-620 (1975)
[7] Larsson, N.J., and Moffat, A., Offline dictionary-based compression, In Data Compression Conference (1999)
[8] Senin, P., Lin, J., Wang, X., Oates, T., Gandhi, S., Boedihardjo, A.P., Chen, C., Frankenstein, S., Time series anomaly discovery with grammar-based compression, In Proc. of the International Conference on Extending Database Technology, EDBT (2015)
If you are using this implementation for your academic work, please cite our GrammarViz 2.0 paper:
[Citation] Senin, P., Lin, J., Wang, X., Oates, T., Gandhi, S., Boedihardjo, A.P., Chen, C., Frankenstein, S., Lerner, M., GrammarViz 2.0: a tool for grammar-based pattern discovery in time series, ECML/PKDD Conference (2014).
